Using SQL in ETL Pipeline (Tutorial)
Overview
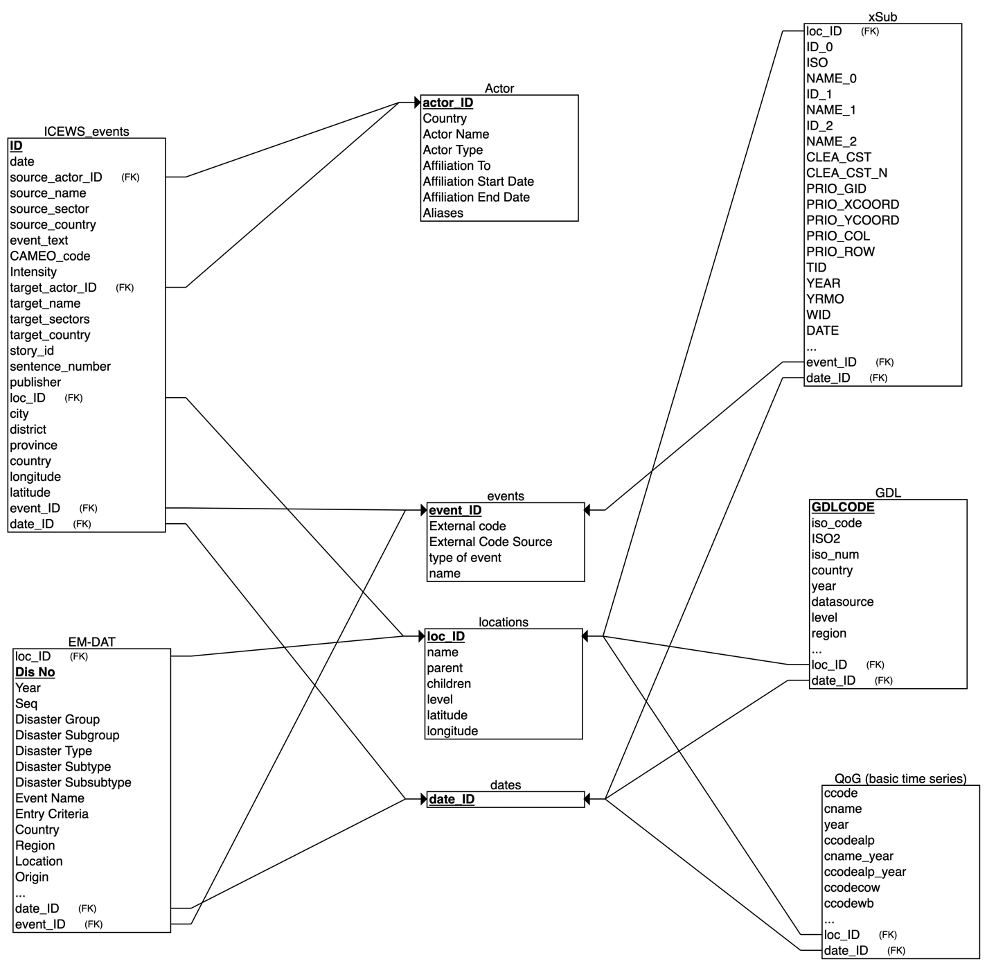
This is a tutorial for using SQL in ETL pipeline based on the logical ERD design I created for a project.
Datasets JOINs
Example:
FULL JOIN icews i ON x."country_ID" = i."country_ID" AND x."YEAR_ID" = i."YEAR_ID" AND x."MONTH_ID" = i."MONTH_ID"
Using SQL JOIN statements, I utilized forigen keys in the database. These forigen keys were added to the database during the Entity Relationship Diagram (ERD) design phase in order to allow cross-table joins. Our forgin keys represent spatiotemporal variables such as country, province, year and month.
WHERE filters
Example:
WHERE x."location_ID" IS NOT NULL
AND x."YEAR_ID" IS NOT NULL
AND x."MONTH_ID" IS NOT NULL
AND x."YEAR_ID" BETWEEN 2000 AND 2020
Using SQL WHERE statements, we can filter out rows where the spatiotemporal variables are empty. Since this SQL query is joining datasets based on the value of the spatiotemporal variables, we need to make sure these values exist or the query will generate data that will not be useful.
Feature Engineering
Last but not the least, I used SQL queries to perform feature engineering as follows: Aggregation Example:
group by l."country_ID", x."YEAR_ID", x."MONTH_ID"
We aggregate the values using the same spatiotemporal that were used in JOIN statements. In order to do this, we cast each of the variables that are not aggregated by the avg function. Dummy variables Example:
sum( case when e."Disaster Type" = 'Volcanic activity' then 1 else 0 end) Volcanic_activity
In the example above, we created a variable called volcanic activity that will have the value 1 whenever the value of Disaster Type is “Volcanic activity”. Afterwards we use sum as our aggregation function in order to capture the full number of volcanic activities in the spatiotemporal aggregation unit.