Twitter NLP Analysis (Tutorial)
Disclaimer
This Demo project was run 7 hours before the Egypt Vs. Saudi Arabia game (PST) that took place on June 25, 2018 in the Russia 2018 World Cup. This project was complied to test “R Codes” in extracting and cleaning tweets in English language.
Overview
I collected random n=500 tweets using Standard Twitter API (https://developer.twitter.com) for the sake of analyzing sentiments based on two hashtags #Egypt and #World Cup starting June 21-25, 2018 in English language. The API returned only randomly selected 500 tweets.
Then, performed data cleaning on tibble format using R(tiday), R(tm) and R(gsub) packages. Sentiment scores are calculated in two different ways: bing and nrc.
The bing lexicon categorizes words into a positive or negative categories; the nrc lexicon categorizes words into emotions like anger, disgust, fear, joy, …etc.
Sentiment text analysis followed the same process using tidytext as shown in the figure below:
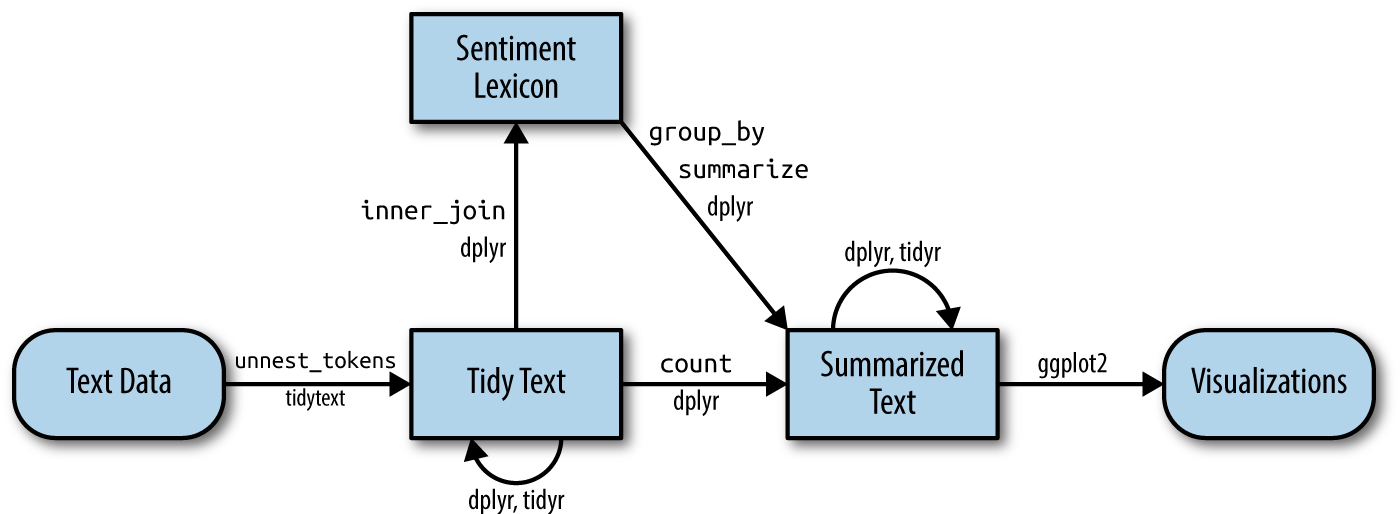
NRC and Bing Scores
This analysis led to generating the following insights.
- Topic modeling based on latent Dirichlet allocation (LDA)
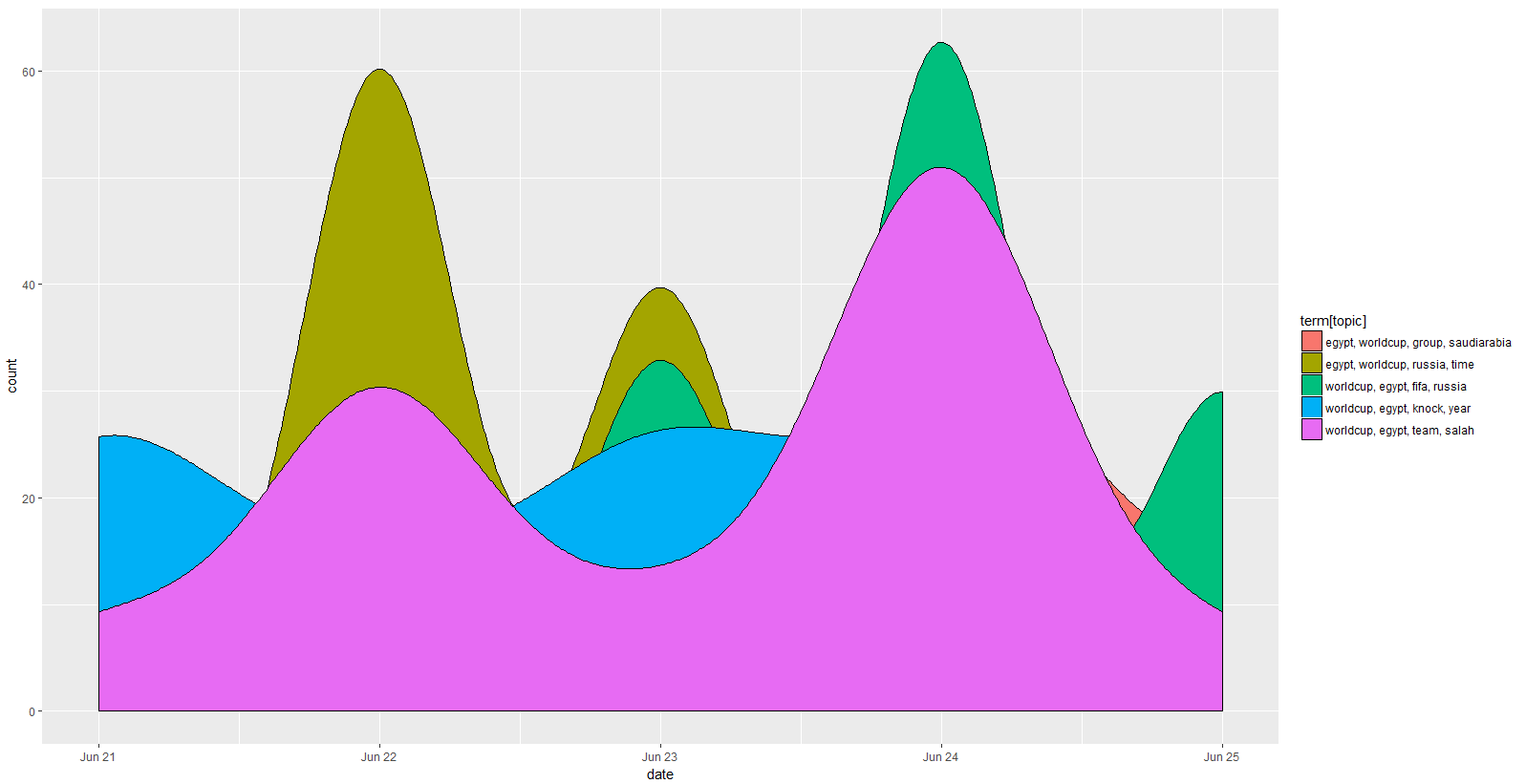
- nrc Sentiment Emotions of Tweets over Time
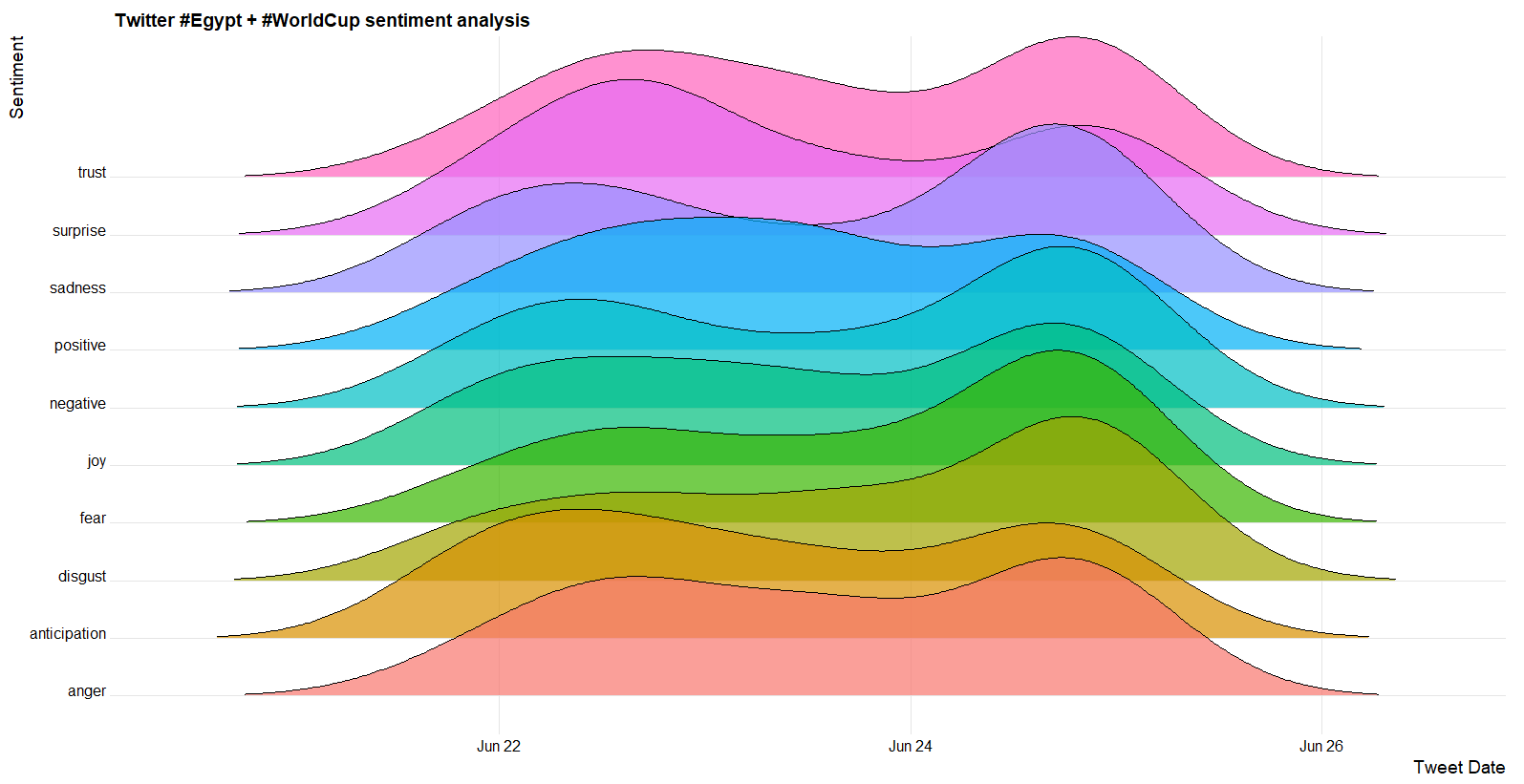
For the full code, click here.