End-to-End Machine Learning Pipeline for Risk Modeling (Architecture)
Overview
In this discussion, I am presenting an end-to-end machine learning pipeline architecture that allows for the automated machine learning experimentation on a uniquely designed SSED database that I created for my PhD work. The end-to-end machine learning pipeline involves the ETL process, Big Data Processing, Feature Engineering, and then production and analysis.
Figure below describes the unique architecture for the end-to-end machine learning pipeline designed for this dissertation and demonstrates its sequential flow. Also, this figure shows the actual products used across the pipeline, which include Google Maps API, Amazon Web Services (AWS), Relational Data Services (RDS) deployment with a PostgreSQL server, Globus SFTP file transfer system, data processing and machine learning platform: H2O.
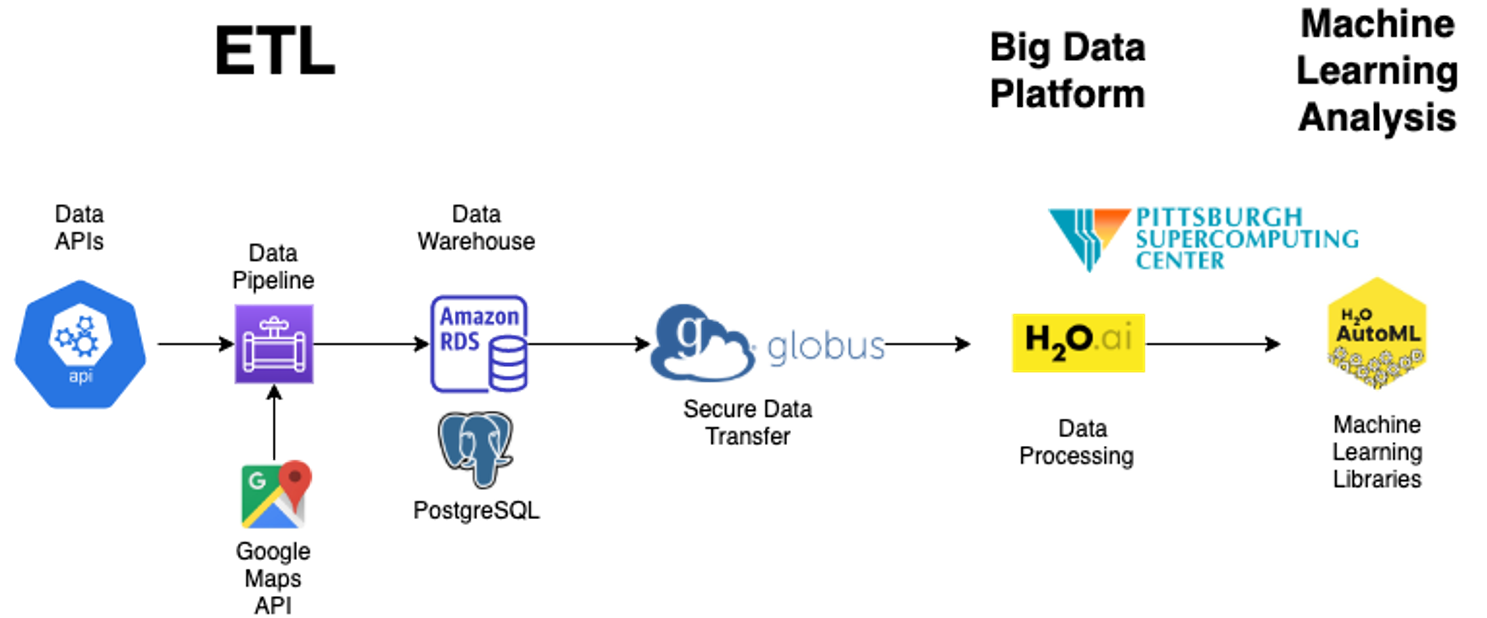
ETL process is meant to be the starting phase in this pipeline, where data are captured from a variety of sources through API endpoints and in text format, then loaded into a data warehouse.
The big data processing and machine learning analysis conducted in this project were performed through the H2O project. Some of the feature engineering was done with the H2O framework and then prepared for machine learning and fine-tuning different models to reach the best fit for this project’s goal.
The computing environment for this dissertation is Amazon Web Services (AWS) in terms of database creation and deployment, and the Pittsburg Supercomputing Center (PSC) Bridges for H2O AutoML computation.